|
Litera
Reference:
Golikov A.A., Akimov D.A., Danilova Y.
Optimization of traditional methods for determining the similarity of project names and purchases using large language models
// Litera.
2024. ą 4.
P. 109-121.
DOI: 10.25136/2409-8698.2024.4.70455 EDN: FRZANS URL: https://en.nbpublish.com/library_read_article.php?id=70455
Optimization of traditional methods for determining the similarity of project names and purchases using large language models
Golikov Aleksei Aleksandrovich
Postgraduate student, Department of Philology and Literature, Department of Russian Language and Literature, Kazan (Volga Region) Federal University (Yelabuga Institute)
109316, Russia, Moscow, Volgogradsky Ave., 42

|
ag@mastercr.ru
|
|
 |
Other publications by this author
|
|
Akimov Dmitrii Andreevich
ORCID: 0009-0004-2800-4430
PhD in Technical Science
Analyst, LLC "Digital solutions workshop"
109316, Russia, Moscow, Volgogradsky ave., 42
|
|
akimovdmitry1@mail.ru
|
|
 |
Other publications by this author
|
|
|
Danilova Yuliya
ORCID: 0000-0001-5736-0590
PhD in Philology
Associate Professor, Department of Russian Language and Literature, Yelabuga Institute (branch) of Kazan Federal University
89 Kazanskaya str., Yelabuga, Republic of Tatarstan, 423604, Russia
|
|
danilovaespu@mail.ru
|
|
|
|
DOI: 10.25136/2409-8698.2024.4.70455
EDN: FRZANS
Received:
09-04-2024
Published:
16-04-2024
Abstract:
The subject of the study is the analysis and improvement of methods for determining the relevance of project names to the information content of purchases using large language models. The object of the study is a database containing the names of projects and purchases in the field of electric power industry, collected from open sources. The author examines in detail such aspects of the topic as the use of TF-IDF and cosine similarity metrics for primary data filtering, and also describes in detail the integration and evaluation of the effectiveness of large language models such as GigaChat, GPT-3.5, and GPT-4 in text data matching tasks. Special attention is paid to the methods of clarifying the similarity of names based on reflection introduced into the prompta of large language models, which makes it possible to increase the accuracy of data comparison. The study uses TF-IDF and cosine similarity methods for primary data analysis, as well as large GigaChat, GPT-3.5 and GPT-4 language models for detailed verification of the relevance of project names and purchases, including reflection in model prompta to improve the accuracy of results. The novelty of the research lies in the development of a combined approach to determining the relevance of project names and purchases, combining traditional methods of processing text information (TF-IDF, cosine similarity) with the capabilities of large language models. A special contribution of the author to the research of the topic is the proposed methodology for improving the accuracy of data comparison by clarifying the results of primary selection using GPT-3.5 and GPT-4 models with optimized prompta, including reflection. The main conclusions of the study are confirmation of the prospects of using the developed approach in the tasks of information support for procurement processes and project implementation, as well as the possibility of using the results obtained for the development of text data mining systems in various sectors of the economy. The study showed that the use of language models makes it possible to improve the value of the F2 measure to 0.65, which indicates a significant improvement in the quality of data comparison compared with basic methods.
Keywords:
TF-IDF, cosine similarity, large language models, GigaChat, GPT-4, textual data analysis, reflexion in prompts, relevance determination, projects and procurement, business process optimization
This article is automatically translated.
You can find original text of the article here.
1. Introduction Solving the problem of determining the similarity of documents or proposals is relevant for a large number of business cases: in recommendation systems, in search engines, chatbots, when checking scientific papers for plagiarism, etc. [1, 2]. In the company of the authors of the article (Workshop of Digital Solutions LLC, Moscow), this task is solved to compare projects and purchases in the electric power industry in Russia by their name. For example, the purchase of "Construction and installation work on the modernization of capacitive current compensation systems at 110 kV Burdun PS for the needs of the branch of JSC Rosseti Tyumen Tyumen Electric Networks" is obviously related to the project "Modernization of capacitive current compensation systems at 110 kV Burdun PS (4 pcs.)" and is not related to the project "Equipment with a complex for ensuring information security of power facilities of PJSC MOESK (stage 5), including PIR (26 pcs.(other))". Solving this problem allows companies wishing to participate in the supply of their materials, components and products for a particular project to find the necessary purchases and take part in relevant tenders, as well as indirectly monitor the progress of the project by the presence or absence of purchases. For customers, this service helps to attract more suppliers and thereby increase competition and improve the terms of purchase. In addition, the solution of the problem corresponds to modern trends in the intelligent processing of large amounts of data, the ongoing digital transformation of enterprises and their business processes. At first glance, the above-mentioned task seems deceptively simple, since it is required to effectively compare not large volumes of text with a complex semantic load, but names in the form of two sentences. However, in fact, this task is rather non-trivial, since the number of projects and purchases in the electric power industry in Russia is measured annually in tens and hundreds of thousands, there are specialized terms, nominations, abbreviations that are not widely represented outside the industry. In addition, the name of the project or purchase often does not contain complete information that allows for an unambiguous comparison. For example, it is not possible to accurately determine whether the project "Creation of an intelligent electric energy metering system within the framework of the execution of Federal Law No. 522-FZ dated December 27, 2018 at the branch of PJSC Rosseti Kuban Ust-Labinsk Electric Networks (5129 t.u.)" and the purchase "The right to conclude a contract for the supply of metering devices" correlate with each other electric energy (capacity) within the framework of fulfilling the requirements of Federal Law No. 522-FZ dated 12/27/2018 to meet the needs of PJSC Rosseti Kuban in 2023,"since it is impossible, based on the names, to unequivocally answer the question whether electric energy metering devices purchased for PJSC Rosseti Kuban for its Ust branch will goLabinsk electric networks specified in the name of the project. Thus, the problem being solved is fuzzy, its answer is not always possible to determine reliably even with the participation of an expert, however, the amount of data being compared at the same time dictates the need to create an algorithmic solution. At the same time, this task is relevant, having great practical significance for customers and suppliers of goods and services not only in the electric power industry, but also in other sectors of the economy, and the methodological approaches used in its successful solution can be used to solve similar problems (for example, to create recommendation systems offering similar purchases with those that the user was interested in, etc.). The object of the study is a database containing the names of projects and purchases (open sources containing investment programs and purchases of electric grid companies were used to collect empirical material), the subject of the study is to determine the relevance of the name of the project to the information content of the purchase. The scientific significance of the research lies in the application of the operational capabilities of large language models as an addition to the classical methods of processing textual information. The purpose of the study is to improve the accuracy of comparing the project and the purchase, and the tasks include analyzing current methods for determining the similarity of two proposals and evaluating the effectiveness of new approaches to the same task. 2. Implementation of an algorithm for determining the similarity of project names and purchases Various methods can be used to solve the problem of determining the similarity of two sentences: 1) methods using character sequence similarity metrics (Jacquard similarity, Levenshtein distance, Jaro-Winkler similarity, etc.) [3, 4]; 2) methods using text conversion to vector representation (Word2vec, TF-IDF), which allows you to calculate the cosine similarity in the next step [5, 6]; 3) methods that also use text conversion to vector representation, but involve deep neural networks with a large number of parameters (BERT, Gigachat, ChatGPT, etc.) [7, 8]. Since, as mentioned above, the annual number of projects and purchases in the Russian electric power industry is measured in tens or even hundreds of thousands per year, the number of pairwise comparisons of the names of each project and purchase can reach 10 billion, which naturally pushes for the use of not too computationally expensive solutions or, at least, to use for the initial selection of potential "project – purchase" pairs, simple and fast methods are sufficient. Simple methods include methods using character sequence similarity metrics, or converting words into vectors using TF-IDF followed by calculating cosine similarity. Obviously, in this case, the second option is more suitable – the calculation of TF-IDF and cosine similarity, since the similarity of the project and the purchase is primarily manifested in words that are rare enough for the body of text under consideration (addresses, names of substations), and not in the similarity of character sequences of the full names of the project and purchase. Recall that TF-IDF (an abbreviation of the English term frequency inverse document frequency, which literally means "the frequency of the term, the inverse frequency of the document") is calculated as the product of two factors – TF and IDF. 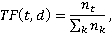
where 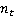 is the number of times the term t occurs in document d; is the number of times the term t occurs in document d; 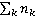 is the total number of terms in document d. That is, TF is a measure of the frequency of verbal reproduction of a term (or other specific nomination) in a document. is the total number of terms in document d. That is, TF is a measure of the frequency of verbal reproduction of a term (or other specific nomination) in a document. 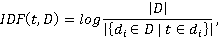
where 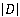 is the total number of documents, is the total number of documents, 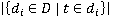 is the number of documents containing the term t. Thus, the IDF reflects the inverse frequency of occurrence of the word in documents: the rarer the word, the greater the IDF. is the number of documents containing the term t. Thus, the IDF reflects the inverse frequency of occurrence of the word in documents: the rarer the word, the greater the IDF. Accordingly, TF-IDF is a product of the above-mentioned TF and IDF indicators and takes a high value for rare terms (for example, names of substations, geographical names) and a low value for frequency terms (service parts of speech, keywords such as "substation", "line", etc.): 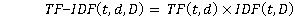
In this case, since a fairly short name of the project or purchase acts as a "document" from the classical definition of TF-IDF, it is permissible to use only the IDF, because in short names within the name itself, a separate term often occurs once, however, the use of the classic TF-IDF indicator gives, as the results of the analysis showed, a similar result. By calculating TF-IDF for each term in the text, it is possible to translate the names of projects and purchases into a vector representation. For example, if there is a project "installation of metering devices" and "purchase of metering devices", then a possible vector representation for the name of the project is a four-dimensional vector {1, 0, 0.5, 0.5}, and for the name of the project {0, 1, 0.5, 0.5}, that is, the general corpus of words consists of four terms, of which two words occur once (higher TF-IDF value) and two words occur twice each (lower TF-IDF value). For a corpus containing thousands of words, the vectors corresponding to individual names of purchases and projects will be sparse, i.e. for almost all coordinates there will be zeros except for coordinates corresponding to the words contained in the name. Further, after determining the vectors corresponding to the names of projects and purchases, it is possible to perform a pairwise calculation of the cosine similarity between each project and each purchase. The cosine similarity between two vectors A and B can be calculated as [9]: 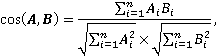
where Ai, Bi are the i-th elements of vectors A and B with dimension n each. Thus, it is possible to obtain all pairwise values of comparisons of projects and purchases, expressed numerically: according to the results of the analysis, it was determined that projects and purchases corresponding to each other occur starting from a cosine similarity of 0.44 and higher (the maximum value of 1 corresponds to completely matching words in the name of the project and purchase). However, not all projects and purchases with a cosine similarity value greater than 0.44 are consistent with each other. We can only note a general trend: the greater the cosine similarity, the more likely it is that the project and the purchase correspond to each other. Therefore, the selection of "project – purchase" pairs by calculating the cosine similarity of vectors obtained on the basis of TF-IDF can be considered initial. In our opinion, it can be optimized by using large language models. API access was implemented to the large language models Gigachat, GPT?3.5, GPT-4 with the following prompt: "Your task is to accurately determine whether there is a connection between the project and the purchase. There is a connection only if the name of the object (with a capital letter) or its number, or the geographical address in the name of the project and the purchase are completely identical. "Project: 'name of the project'. Purchase: 'name of the purchase'. Is there an exact connection between them?"" Subsequently, according to the results of the analysis, the quality of the work of large language models was improved due to such a well-known technique as the introduction of reflection [10], namely, the prompta was added: "If the answer is yes, be prepared to specify exactly what the connection is. In case of an answer 'No,' be ready to explain why not." To be able to process the model's response automatically, the response format must be fixed, because otherwise a large language model may respond with a long sentence unsuitable for subsequent automatic processing. To do this, the prompt was added: "Answer 'yes' or 'no' in JSON format. For example: {'answer': 'yes'}". Thus, the final pipeline for processing project and procurement data looks like this (Figure 1). 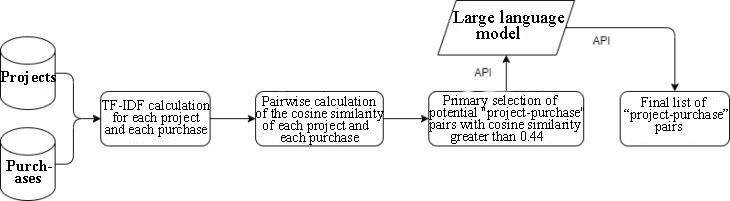
Figure 1: Pipeline algorithm for determining projects and purchases that correspond to each other Here is an example of how this algorithm works. For the name of each project and each purchase, a TF-IDF calculation is performed, on the basis of which a pairwise calculation of the cosine similarity of each project and each purchase is performed, which allows for the initial selection of potential "project – purchase" pairs with a cosine similarity of more than 0.44. Then, for all selected pairs, an API request is made to the large language model. Let's take as an example a pair consisting of the project "Modernization of PS 110/35/10 kV Prechistoe with installation of video surveillance equipment" and the purchase of "The right to conclude a Contract for construction and installation works on objects: "Modernization of PS 110/35/10 kV Prechistoe, PS 110/35/10 kV Yershichi, PS 110/35/10 kV Kasplya with installation of video surveillance equipment" for the needs of PJSC Rosseti Center". The final text of the request to the large language model is as follows: "Your task is to determine exactly whether there is a connection between the project and the purchase. There is a connection only if the name of the object (with a capital letter) or its number, or the geographical address in the name of the project and the purchase are completely identical. Project: "Modernization of the 110/35/10 kV Prechistoe substation with installation of video surveillance equipment". Purchase: "The right to conclude a Contract for the performance of construction and installation works on objects: "Modernization of PS 110/35/10 kV Prechistoe, PS 110/35/10 kV Yershichi, PS 110/35/10 kV Kasplya with installation of video surveillance equipment" for the needs of PJSC Rosseti Center". Is there an exact connection between them?". If the answer is 'yes', be prepared to specify exactly what the connection is. In case of an answer 'No,' be ready to explain why not. Answer 'yes' or 'no' in JSON format. For example: {'answer': 'yes'}". The answer of the GPT-4 model in this case is "{'answer': 'yes'}". Thus, from those initially selected "project – purchase" pairs for which the large language model answered "{'answer': 'yes'}", the final list of "project – purchase" pairs is formed. 3. Results and discussion
To evaluate the results, you should choose the appropriate metric for this task of determining relevant project– purchase pairs. Obviously, the ideal result would be to classify all relevant project–purchase pairs as relevant and the rest as irrelevant. However, in practice, achieving such an ideal result in this task is unlikely, since 2 types of errors are possible [12, 13]: The first kind of error is a false positive result, False Positive, FP: the algorithm determines the "project – purchase" pair as relevant, while in fact the pair is irrelevant. The second kind of error is a false negative result, False Negative, FN: the algorithm determines the "project – purchase" pair as irrelevant, while in fact the pair is relevant. From the point of view of business logic, in this task, a false positive result (to output an irrelevant purchase for the project) is a less gross error than a false negative result (not to output a relevant purchase for the project). In such cases, completeness (recall) is often chosen as a metric [14, 15]: 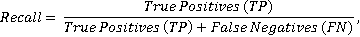
where TP is the number of correctly identified relevant pairs, FN is the number of relevant pairs that were marked as irrelevant by the algorithm. However, when using such a metric, too much priority is given to avoiding false negative results – the number of false positive results does not affect the final result in any way, and if the algorithm marks all project– purchase pairs as relevant, then the completeness metric will be maximum. Another commonly used metric is precision: 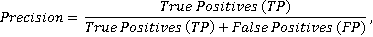
where TP is the same as in the completeness formula, FP is the number of irrelevant pairs that were marked as relevant by the algorithm. This metric is even less suitable for us, because the number of false negative results, which we strive to avoid more than false positive ones, is not estimated at all. Therefore, for us, the optimal metric will be a metric that combines the metrics of completeness and accuracy, but with a shift in importance in favor of completeness (the priority is to avoid false negative results). In this case, the so-called F2 measure is often used [Bystrov et al., 2022, pp. 140-141]: 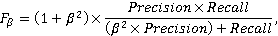
where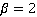 . . From the results of the initial selection of potential project–purchase pairs by calculating TF-IDF and pairwise calculation of cosine similarity, a random sample of 100 project–purchase pairs with cosine similarity of at least 0.44 was formed – the value starting from which the relevant pairs occur. Among these 100 pairs, only 18% turned out to be actually relevant, which can be considered a relatively acceptable result for a fast computationally not too expensive method, given the large size of the initial project and procurement databases (tens of thousands of records each). The use of large language models at the second stage according to the scheme described in Section 2 allows us to achieve the following values of the F2 measure in the task of classifying relevant and irrelevant project–purchase pairs (Figure 2). 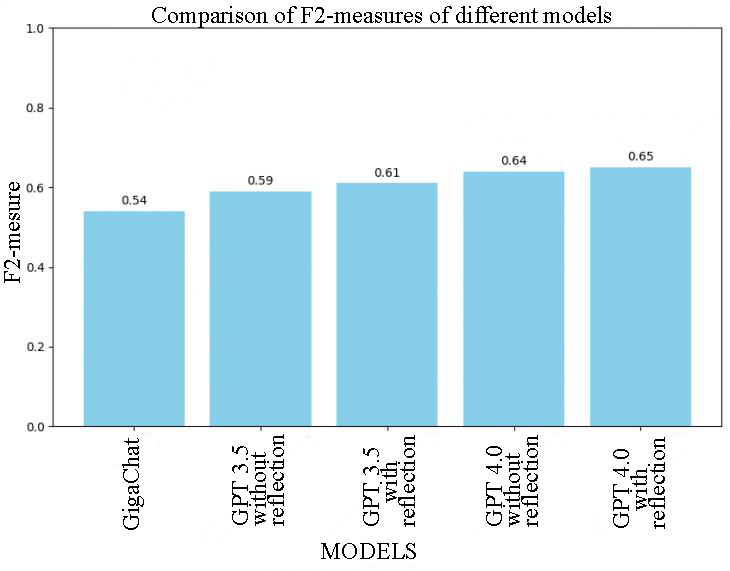
Figure 2: Values of the F2 measure in the task of classifying project-purchase pairs using various large language models and prompta The GigaChat model demonstrated the worst result: the value of the F2 measure was only 0.54, while the model practically does not allow to improve the primary selection, since, according to the GigaChat model, 96 pairs out of 100 are relevant. The best result (Table 1) The GPT-4 model was achieved by using the reflection block in the prompt described in section 2. | | Predicted is relevant | Predicted is irrelevant | | Really relevant | 12 | 6 | | Really irrelevant |
9 | 73 | Table 1: Error matrix (confusion matrix) of the GPT-4 model with reflection The results of the GPT-4 model shown in Table 1 can be described as follows: - True Positives (TP): 12 – really relevant pairs, correctly classified as relevant (for example: The project "Technical re-equipment of KTP 10/0.4 kV No.476 f.01 PS 35/10 kV Ryshkovo with the replacement of a power transformer 100 to 100 kVA p.Ryshkovo Zheleznogorsk district (transformer capacity 0.1 MVA)" and purchase "Implementation of the SMR for the facility: Technical re-equipment of KTP 10/0.4 kV No.476 F.01 PS 35/10 kV Ryshkovo with replacement of a power transformer 100 to 100 kVA P.Ryshkovo Zheleznogorsk district"); - True Negatives (NP): 73 – really irrelevant pairs, correctly classified as irrelevant (for example: The project "Purchase of 110kV column gas switches in the CAR – 5 pcs." and the purchase "Purchase of 110kV voltage measuring transformers in the CAR – 9 pcs."); - False Positives (FP): 9 – irrelevant pairs, mistakenly classified as relevant (for example: The project "Reconstruction of the 500 kV Ust-Kut substation with a 500 kV SHR installation with a capacity of 180 Mvar for 500 kV Ust-Ilimskaya HPP-Ust-Kut No. 3" and the purchase "The right to conclude a work contract according to RD, SMR, NDP, supply of equipment for the construction of electronic warfare under the title "Construction of 220 kV Ust-Kut – Kovykta overhead lines No. 1 and No. 2 with an estimated length of 256 km each"); - False Negatives (FN): 6 – relevant pairs, mistakenly classified as irrelevant (for example: The project "Modernization of equipment of power facilities and RDP 12 RER of the ISS-branch of PJSC MOESK, including PIR: Moscow (6 pcs.(other))" and procurement "Execution of the CMP, NDP, materials, equipment by title: Modernization of equipment of power facilities and RDP 22 RER of the ISS-branch of PJSC MOESK, including PIR: Moscow (4 pcs.(other))"). Thus, 85 project–purchase pairs out of 100 are classified correctly by the GPT-4 model. For example: - The project "Technical re-equipment of KTP 10/0.4 kV No.476 f.01 PS 35/10 kV Ryshkovo with replacement of a power transformer 100 by 100 kVA p.Ryshkovo Zheleznogorsk district (transformer capacity 0.1 MVA)" and purchase "Implementation of the SMR for the facility: Technical re-equipment of KTP 10/0.4 kV No.476 f.01 PS 35/10 kV Ryshkovo with replacement of a power transformer 100 to 100 kVA P.Ryshkovo Zheleznogorsk district"; - The project "Modernization of capacitive current compensation systems at 110 kV Burdun substation (4 pcs.)" and the purchase "Execution of construction and installation works on modernization of capacitive current compensation systems at 110 kV Burdun substation for the needs of the branch of JSC Roseti Tyumen Tyumen Electric Networks". This result can be regarded as satisfactory, since it allows you to reflect relevant purchases much more accurately for users. However, it should be noted that the relatively high value of false negative results is 6 pairs (type: Project "Modernization of equipment of power facilities and RDP 12 RER of the ISS–branch of PJSC MOESK, including PIR: Moscow (6 pcs.(other))" and purchase "Execution of the CMP, NDP, materials, equipment by title: Modernization of equipment of power facilities and RDP 22 RER of the ISS-branch of PJSC MOESK, including PIR: Moscow (4 pcs.(other))"), i.e. a third of relevant pairs are incorrectly marked as irrelevant, which obviously leaves significant potential for further improvement in the quality of differentiation of project–purchase pairs into (non-)relevant ones. It is also worth noting the relative high cost of API access to the GPT-4 model (processing 100 pairs of "project – purchase" costs about $ 0.62), although with the development of models there is a tendency to reduce the cost of their use. Thus, the use of large language models is a promising tool that can significantly improve the results of faster, but less accurate traditional approaches to processing text data. The most adequate model for the problem under consideration turned out to be the GPT-4 model with an added reflection block, which correctly classified 85 project–purchase pairs out of 100. At the same time, the relative large number of false negative results and the achieved value of the F2 measure (0.65) indicate that there remains a wide space for a clearer and more accurate differentiation of project–purchase pairs into (non-)relevant ones. 4. Conclusion The paper investigated the actual task of determining by name relevant purchases for the business process, in particular, for investment projects in the field of electric power industry. Its solution will have a positive impact on the market conditions of the industry, will allow suppliers of materials and equipment to more effectively find suitable tenders for participation, and customers to attract more suppliers. In addition, effective methods of solving the problem can be applied in other sectors of the economy.
Possible approaches to determining the similarity of two proposals were considered, and the use of a computationally fast method at the first stage was justified, consisting in translating the names of projects and purchases into a vector representation by calculating the TF-IDF metric of each name and subsequent pairwise calculation of the cosine similarity of all projects and purchases with cutting off all pairs of "project – purchase" with cosine similarity above 0.44 (below 0.44, relevant pairs, as shown by sample analysis, do not occur). However, out of 100 project–purchase pairs selected in this way, only 18 are relevant on average, which dictates the need for further differentiation of project–purchase pairs into relevant and irrelevant ones. At the second stage, various large language models were tested with one of the possible prompta and the addition of a model reflection block to it. It was found that the GigaChat model practically does not lead to an improvement in primary selection, while the GPT-4 model with a reflection unit shows the best results (the value of the F2 measure is 0.65). It has been demonstrated that reflection slightly improves the performance of large language models (the value of the F2 measure improves by 0.01-0.02). The control of the response format of the model was carried out by adding an instruction to the prompt to respond in JSON format. The authors plan to continue the research in order to further optimize the algorithm for comparing projects and purchases, both by clarifying prompta to address large language models (there are other options for improving prompta besides introducing a reflection block), and using additional classification algorithms based on manually marked data: for example, a gradient boosting model with features such as the lengths of project names and purchases, the number of capital letters in the names of projects and purchases, etc.
References
1. Oskina, K. A. (2016). Optimisation of the tf-idf-based text classification method by introducing additional coefficients. Bulletin of the Moscow State Linguistic University. Humanities, (15 (754)), 175-187.
2. Murugesan, M., Jiang, W., Clifton, C., Si, L., & Vaidya, J. (2010). Efficient privacy-preserving similar document detection. The VLDB Journal, 19(4), 457-475.
3. Znamensky, S. V. (2017). Model and axioms of similarity metrics. Software systems: theory and applications, 8(4 (35)), 347-357.
4. Gaidamakin, N. A. (2016). A measure of similarity of sequences of the same dimension. Mathematical Structures and Modelling, (4 (40)), 5-16.
5. Lychenko, N. M., & Sorokovaya, A. V. (2019). Comparison of the effectiveness of word vector representation methods for text tone detection. Mathematical Structures and Modelling, (4 (52)), 97-110.
6. Jurgens, D. (2021, June). Learning about word vector representations and deep learning through implementing word2vec. In Proceedings of the Fifth Workshop on Teaching NLP (pp. 108-111).
7. Salyp, B. Y., & Smirnov, A. A. (2022). Analysing the BERT model as a tool for determining a measure of semantic proximity of natural language sentences. StudNet, 5(5), 3509-3518.
8. Savenkov, P. A., & Ivutin, A. N. (2022). Methods of analysis of natural language in tasks of detecting povedential anomalies. Izvestiya Tulskogo gosudarstvennogo universiteta. Technical Sciences, (3), 358-366.
9. Valiev, A. I., & Lysenkova, S. A. (2021). Application of machine learning methods to automate the process of text content analysis. Vestnik cybernetiki, (4 (44)), 12-15.
10. Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., & Yao, S. (2024). Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36.
11. Stepanov, A. S., & Stepanov, S. M. (2010). On the meaning of errors of the first and second kind. Actual problems of aviation and cosmonautics, 1(6), 239-241.
12. Savinov, A. N., & Ivanov, V. (2011). Analysis of the solution of problems of occurrence of errors of the first and second kind in systems of recognition of keyboard handwriting. Vestnik Volga University named after VN Tatishchev, (18), 120-125.
13. Zaikin, D. A. (2014). An approach to ranking results for terminological search. Uchenye zapiski Kazan University. Series of Physical and Mathematical Sciences, 156(1), 12-21.
14. Wang, R., & Li, J. (2019, July). Bayes test of precision, recall, and F1 measure for comparison of two natural language processing models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 4135-4145).
15. Bystrov, I. S., & Kotenko, I. V. (2022). Indicators for evaluating machine learning performance as applied to the task of cyber-insider detection. In Regional Informatics (RI-2022) (pp. 140-141).
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The reviewed article is aimed at a practical solution to the problem of optimizing traditional methods for determining the similarity of project names and purchases using large language models. The author sets a goal that is relevant and significant in modern conditions. The object of the study is a database containing the names of projects and purchases (open sources containing investment programs and purchases of electric grid companies were used to collect empirical material), the subject of the study is to determine the relevance of the name of the project to the information content of the purchase. It is worth agreeing that "the scientific significance of the study lies in the application of the operational capabilities of large language models as an addition to the classical methods of processing textual information." The practical nature of the work has been started: "various methods can be used to solve the problem of determining the similarity of two sentences: 1) methods using character sequence similarity metrics (Jacquard similarity, Levenshtein distance, Jaro-Winkler similarity, etc.) [3, 4]; 2) methods using text conversion to vector representation (Word2vec, TF-IDF), which allows you to calculate cosine similarity at the next step [5, 6]; 3) methods that also use text conversion to vector representation, but involve deep neural networks with a large number of parameters (BERT, Gigachat, ChatGPT, etc.) [7, 8]". The research methodology is syncretic, the article uses mathematical principles of consideration and argumentation of the problem. The general data block is fully included; I believe that the material can be used further. Judgments in the course of work are objective, verified: for example, "API access to large Gigachat, GPT 3.5, GPT-4 language models was implemented with the following prompt: "Your task is to accurately determine whether there is a connection between the project and the purchase. There is a connection only if the name of the object (with a capital letter) or its number, or the geographical address in the name of the project and the purchase are completely identical. "Project: 'name of the project'. Purchase: 'name of the purchase'. Is there an exact connection between them?"", or "Let's give an example of how this algorithm works. For the name of each project and each purchase, a TF-IDF calculation is performed, on the basis of which a pairwise calculation of the cosine similarity of each project and each purchase is performed, which allows for the initial selection of potential "project – purchase" pairs with a cosine similarity of more than 0.44. Then, for all selected pairs, an API request is made to the large language model. Let's take as an example a pair consisting of the project "Modernization of PS 110/35/10 kV Prechistoe with installation of video surveillance equipment" and the purchase of "The right to conclude a Contract for construction and installation works on objects: "Modernization of PS 110/35/10 kV Prechistoe, PS 110/35/10 kV Yershichi, PS 110/35/10 kV Kasplya with installation of video surveillance equipment" for the needs of PJSC Rosseti Center, etc. Examples are given in the so-called open data mode; the actual level is taken into account. The work is divided into semantic /standard parts, the general logic is maintained throughout the study. The generalization of the obtained data is presented in the form of tables, diagrams, graphs, and figures. The conclusions of the intermediate type are consistent with the final ones: "the use of large language models is a promising tool that allows significantly improving the results of faster, but less accurate traditional approaches to processing text data. The most adequate model for the problem under consideration turned out to be the GPT-4 model with an added reflection block, which correctly classified 85 project–purchase pairs out of 100. At the same time, the relative large number of false negative results and the achieved value of the F2 measure (0.65) indicate that there remains a wide space for a clearer and more accurate differentiation of project-purchase pairs into (non–)relevant ones." The overall result is very successful regarding the fact that work in this direction should be continued: "the authors plan to continue the study in order to further optimize the algorithm for comparing projects and purchases both by clarifying prompta to address large language models (there are other options for improving prompta in addition to introducing a reflection block), and using additional classification algorithms based on manually marked up data: for example, a gradient boosting model with features such as the length of project and procurement names, the number of capital letters in project and procurement names, etc." The requirements of the publication are taken into account; the purpose of the work has been achieved; the set range of tasks has been solved. I recommend the article "Optimization of traditional methods for determining the similarity of project names and purchases using large language models" for open publication in the journal "Litera".
|

 Eng
Eng









