|
Software systems and computational methods
Reference:
Simankov V.S., Drilenko M.V.
Integration of information resources of situational centers
// Software systems and computational methods.
2021. ą 4.
P. 58-67.
DOI: 10.7256/2454-0714.2021.4.34845 URL: https://en.nbpublish.com/library_read_article.php?id=34845
Integration of information resources of situational centers
Simankov Vladimir Sergeevich
Doctor of Technical Science
Professor, the department of Computer Technologies and Information Security, Kuban Technological University
350072, Russia, Krasnodarskii krai, g. Krasnodar, ul. Moskovskaya, 2

|
sv@simankov.ru
|
|
 |
|
Drilenko Maxim Vladimirovich
Postgraduate student, the department of Computer Technologies and Information Security, Kuban Technological University
350072, Russia, Krasnodarskii krai, g. Krasnodar, ul. Moskovskaya, 2
|
|
dril.max@rambler.ru
|
|
|
|
DOI: 10.7256/2454-0714.2021.4.34845
Received:
12-01-2021
Published:
31-12-2021
Abstract:
The existing approaches towards formation of a single information space for accessing from various information resources are not effective enough from the economic and operational perspective. The subject of this research is the information assets from different sources used for the work of intelligent situational centers. The goal lies in the development of methodology for unification of such resources into a single information space, which is essential for the processing of large volumes of unstructured and poorly structured information. The article explores the models and types of data, information space of the activity for determining the end type of data representation, and the algorithm of transitioning from the object to NoSQL model. As a result of the conducted research, the author built a new information structure of the intelligent situational center. The proposed methodology for the formation of physical data models is compatible with the four types of NoSQL databases: columns, documents, graphs, and a key value. The data models (conceptual, logical, and physical) used in the developed process comply with the meta-models: from conceptual to logical stage, followed by from logical to physical stage. The offered solution should be implemented in the form of a hardware-in-the-loop complex that utilizes the described methodology for integrating the information flows from various situational centers. This would ensure the adaptive dynamic transformation of incoming data and their further use within the situational center.
Keywords:
data integration, intelligent situational centers, data processing, data analysis, data structuring, situation center consolidation, information flow consolidation, data models, meta-models, NoSQL
This article written in Russian. You can find original text of the article here
.
Ââĺäĺíčĺ
 íŕńňî˙ůĺĺ âđĺě˙ ńóůĺńňâóţň îňäĺëüíűĺ ďîäőîäű ę ôîđěčđîâŕíčţ ĺäčíîăî číôîđěŕöčîííîăî ďđîńňđŕíńňâŕ äë˙ äîńňóďŕ čç đŕçëč÷íűő číôîđěŕöčîííűő đĺńóđńîâ, ęîňîđűĺ ďđĺäńňŕâëĺíű â âčäĺ ńôîđěčđîâŕííűő âđó÷íóţ óíčęŕëüíűő ŕëăîđčňěîâ ďđĺîáđŕçîâŕíč˙ ňŕáëčö čç đŕçëč÷íűő čńňî÷íčęîâ. Ňŕęîé ďîäőîä âűçűâŕĺň ďîňđĺáíîńňü â íŕđŕůčâŕíčč îđăŕíčçŕöčîííűő đĺńóđńîâ ďđč ďî˙âëĺíčč íîâűő çíŕ÷čňĺëüíűő îáúĺěîâ íĺńňđóęňóđčđîâŕííîé číôîđěŕöčč, ÷ňî ďđčâîäčň ę ýęîíîěč÷ĺńęčě č îďĺđŕöčîííűě ďîňĺđ˙ě, ÷ňî íĺâîçěîćíî â óńëîâč˙ő ôóíęöčîíčđîâŕíč˙ číňĺëëĺęňóŕëüíîăî ńčňóŕöčîííîăî öĺíňđŕ.
Ňŕęčě îáđŕçîě, ńóůĺńňâóĺň íĺîáőîäčěîńňü ńîâĺđřĺíńňâîâŕíč˙ ěĺňîäč÷ĺńęčő ďîëîćĺíčé îáúĺäčíĺíč˙ číôîđěŕöčîííűő đĺńóđńîâ čç đŕçëč÷íűő čńňî÷íčęîâ äë˙ đĺřĺíč˙ đŕçëč÷íűő ďđčęëŕäíűő çŕäŕ÷.
Čńńëĺäîâŕíčĺ çŕđóáĺćíîé ëčňĺđŕňóđű [1–4] ďî äŕííîé ňĺěŕňčęĺ ďîęŕçűâŕĺň, ÷ňî íŕó÷íűĺ čçűńęŕíč˙ íŕďđŕâëĺíű íŕ ŕâňîěŕňč÷ĺńęîĺ ďđčâĺäĺíčĺ äŕííűő ę ĺäčíîé ńňđóęňóđĺ. Îäíŕęî đŕçíîîáđŕçčĺ čěĺţůčőń˙ ňčďîâ äŕííűő íĺ ďîçâîë˙ĺň ńôîđěčđîâŕňü ĺäčíűé ďîäőîä äë˙ îáđŕáîňęč ďîëó÷ŕĺěîé číôîđěŕöčč (đčń. 1).
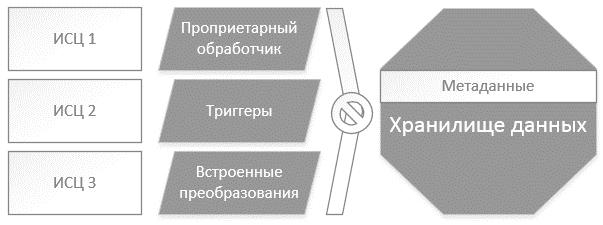
Đčń. 1. Ďđĺäńňŕâëĺíčĺ äŕííűő
Öĺëüţ äŕííîé đŕáîňű ˙âë˙ĺňń˙ ôîđěčđîâŕíčĺ ěĺňîäčęč îáúĺäčíĺíč˙ číôîđěŕöčîííűő đĺńóđńîâ čç đŕçëč÷íűő čńňî÷íčęîâ äë˙ đĺřĺíč˙ çŕäŕ÷ číňĺëëĺęňóŕëüíîăî ńčňóŕöčîííîăî öĺíňđŕ, ÷ňî íĺîáőîäčěî č âŕćíî ďđč îáđŕáîňęĺ áîëüřčő îáúĺěîâ íĺńňđóęňóđčđîâŕííîé číôîđěŕöčč.
1. Ěîäĺëč č ňčďű äŕííűő
Äë˙ äîńňčćĺíč˙ ďîńňŕâëĺííîé öĺëč â đŕáîňĺ ňđĺáóĺňń˙ îńóůĺńňâčňü čńńëĺäîâŕíčĺ íĺńňđóęňóđčđîâŕííűő číôîđěŕöčîííűő ďîňîęîâ č čő ńňđóęňóđű, âűäĺëčňü îńîáĺííîńňč č ěîäĺëč ňŕęčő äŕííűő, čçó÷čňü âîçěîćíîńňč ďđĺîáđŕçîâŕíč˙ â đŕçëč÷íűĺ ôîđěű ďđĺäńňŕâëĺíč˙.
Ěîäĺëü äŕííűő — ýňî ńőĺěŕ îďčńŕíč˙ ńňđóęňóđű äŕííűő äë˙ ęîíĺ÷íîăî ďîňđĺáčňĺë˙ (ďđčëîćĺíč˙, áŕçű äŕííűő). Ěîäĺëü ńîäĺđćčň ňčďű č ńňđóęňóđű, ńîâîęóďíîńňü îďĺđŕöčé, íŕęëŕäűâŕĺěűĺ íŕ ňčďű îăđŕíč÷ĺíč˙ [5].
Ńňđóęňóđčđîâŕííűĺ äŕííűĺ čěĺţň îďđĺäĺëĺííűĺ îăđŕíč÷ĺíč˙ äë˙ ęŕćäîăî ŕňđčáóňŕ, ęîňîđűĺ óńëîćí˙ţň ěîäčôčęŕöčţ ěîäĺëč â ńîîňâĺňńňâčč ń íîâűěč ňđĺáîâŕíč˙ěč. Ńňđóęňóđŕ ňŕęčő äŕííűő îďđĺäĺëĺíŕ ń ďîěîůüţ ńőĺě äŕííűő, ŕâňîěŕňč÷ĺńęîĺ ďđĺîáđŕçîâŕíčĺ çŕňđóäíčňĺëüíî [6].
Ńëŕáîńňđóęňóđîâŕííűĺ äŕííűĺ čěĺţň íĺďîëíóţ ńňđóęňóđó, čěĺţň čńęëţ÷ĺíč˙, çíŕ÷ĺíč˙ ńęŕë˙đíűő ďîëĺé çŕ÷ŕńňóţ ďđĺäńňŕâëĺíű â âčäĺ ňĺęńňîâîé číôîđěŕöčč. Äîďîëíčňĺëüíî âîçíčęŕĺň ďđîáëĺěŕ îďđĺäĺëĺíč˙ ďđčíŕäëĺćíîńňč äŕííűő, ňđĺáóĺňń˙ äîďîëíčňĺëüíŕ˙ âĺđčôčęŕöč˙ čäĺíňčôčöčđîâŕííîăî äîęóěĺíňŕ.
Íĺńňđóęňóđčđîâŕííűĺ äŕííűĺ ďđĺäńňŕâëĺíű ďîëíîńňüţ îňńóňńňâóţůĺé ńňđóęňóđîé č îăđŕíč÷ĺíč˙ěč ďđčěĺíčěűő îďĺđŕöčé ń íčěč. Ŕâňîěŕňč÷ĺńęîĺ čçěĺíĺíčĺ ńňđóęňóđű ňŕęčő äŕííűő íĺ ěîćĺň áűňü âűďîëíĺíî.
Ďđĺäńňŕâëĺíčĺ íŕęîďëĺííîé číôîđěŕöčč â ďđĺëîěëĺíčč ę ęŕćäîěó ňčďó äŕííűő (ńňđóęňóđčđîâŕííűő, ďîëóńňđóęňóđčđîâŕííűő, íĺńňđóęňóđčđîâŕííűő) ďîęŕçŕíî íŕ đčń. 2 [7].
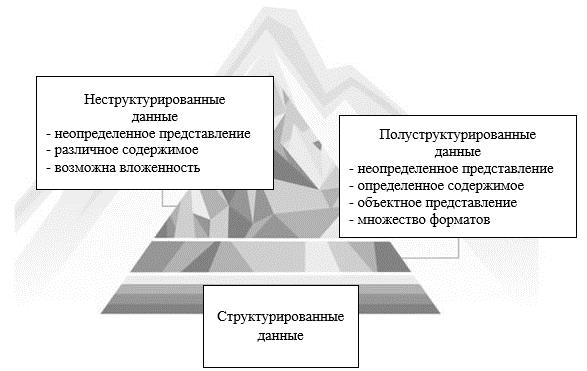
Đčń. 2. Ńőĺěŕ äŕííűő
 ńëŕáîńňđóęňóđîâŕííűő äŕííűő ŕňđčáóňű ěîăóň áűňü ńôîđěčđîâŕíű â âčäĺ ňĺęńňŕ, ńëĺäîâŕňĺëüíî, íĺîáőîäčě íŕäĺćíűé ěĺőŕíčçě ďđîâĺđęč ńîďîńňŕâëĺíč˙ äŕííűő ęîíęđĺňíîěó ŕňđčáóňó. Ńőĺěŕ ěîćĺň íĺ â ďîëíîé ěĺđĺ îňâĺ÷ŕňü îáđŕáŕňűâŕĺěîé číôîđěŕöčč [2, 8]. Đŕáîňŕňü ń äîęóěĺíňîě, íĺ čěĺ˙ ďđĺäńňŕâëĺíčé î ĺăî ńňđóęňóđĺ, çŕňđóäíčňĺëüíî, âîçíčęŕĺň çŕäŕ÷ŕ îďđĺäĺëĺíč˙ ńőĺěű îáđŕáŕňűâŕĺěűő ěŕńńčâîâ číôîđěŕöčč, čő đŕńďîçíŕâŕíč˙ â ďđîöĺńńĺ čńďîëüçîâŕíč˙ ěîäĺëč äë˙ ďîëó÷ĺíč˙ íîâîé číôîđěŕöčč. Äîďîëíčňĺëüíî ŕňđčáóňű ěîăóň íĺ ńóůĺńňâîâŕňü čëč íĺ óäîâëĺňâîđ˙ňü óńëîâč˙ě ęîđđĺęňíîńňč äŕííűő, çŕäŕííűě äë˙ ýňčő ŕňđčáóňîâ. Ňŕęčě îáđŕçîě, â ôîđěčđóĺěîé ěîäĺëč äîëćíű čńďîëüçîâŕňüń˙ číńňđóěĺíňű îáđŕáîňęč čńęëţ÷ĺíčé, ęîňîđűé ďîçâîë˙ň óńňŕíîâčňü ńňđóęňóđó çŕďđîńŕ ę ňŕęčě äŕííűě, čńďîëüçó˙ çŕäŕííűĺ ęđčňĺđčč.
Äë˙ ďĺđĺőîäŕ ę ĺäčíîěó číôîđěŕöčîííîěó ďđîńňđŕíńňâó íĺîáőîäčěî čńďîëüçîâŕňü îáůóţ ěîäĺëü äŕííűő óíčâĺđńŕëüíîăî őđŕíčëčůŕ [9, 14], ęîňîđŕ˙ ôîđěčđóĺňń˙ ďîńëĺäîâŕňĺëüíî č ńîńňîčň čç ęîíöĺďňóŕëüíîé, ëîăč÷ĺńęîé č ôčçč÷ĺńęîé ěîäĺëč äŕííűő. Ďĺđĺőîä ěĺćäó ěîäĺë˙ěč îńóůĺńňâë˙ĺňń˙ ďîńëĺäîâŕňĺëüíî.
Ęîíöĺďňóŕëüíŕ˙ ěîäĺëü óíčâĺđńŕëüíîăî őđŕíčëčůŕ äŕííűő đŕńńěŕňđčâŕĺňń˙ ęŕę îďčńŕíčĺ îńíîâíűő îáúĺęňîâ č ńâ˙çĺé ěĺćäó íčěč [10]. Ęîíöĺďňóŕëüíŕ˙ ěîäĺëü îňđŕćŕĺň ďđĺäěĺňíóţ îáëŕńňü â đŕěęŕő ďëŕíčđóĺěîăî óíčâĺđńŕëüíîăî őđŕíčëčůŕ äŕííűő [11, 12].
Ëîăč÷ĺńęŕ˙ ěîäĺëü đŕńřčđ˙ĺň ęîíöĺďňóŕëüíóţ ďóňĺě îďđĺäĺëĺíč˙ ńóůíîńňĺé ŕňđčáóňîâ, čő îďčńŕíčé č îăđŕíč÷ĺíčé, óňî÷í˙ĺň ńîńňŕâ ńóůíîńňĺé č âçŕčěîńâ˙çč ěĺćäó íčěč.
Ôčçč÷ĺńęŕ˙ ěîäĺëü äŕííűő îďčńűâŕĺň đĺŕëčçŕöčţ îáúĺęňîâ ëîăč÷ĺńęîé ěîäĺëč íŕ óđîâíĺ îáúĺęňîâ ęîíęđĺňíîé áŕçű äŕííűő, íŕ íĺé ńňđîčňń˙ âçŕčěîäĺéńňâčĺ ďîäńčńňĺě âčđňóŕëüíîăî óđîâí˙ č óđîâí˙ ďđčëîćĺíčé (đčń. 3).
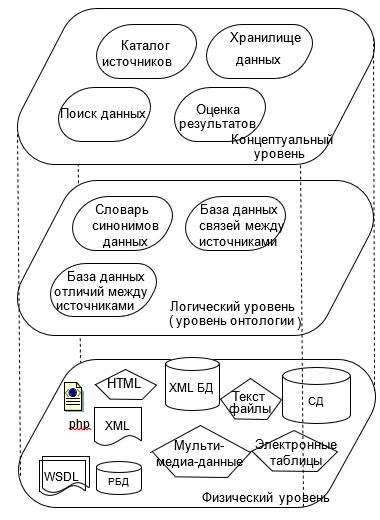
Đčń. 3. Óđîâíč đĺŕëčçŕöčč ôčçč÷ĺńęîé ěîäĺëč ďđîńňđŕíńňâŕ äŕííűő
2. Číôîđěŕöčîííîĺ ďđîńňđŕíńňâî
Äë˙ đŕáîňű ń íĺńňđóęňóđčđîâŕííîé čëč ńëŕáîńňđóęňóđčđîâŕííîé číôîđěŕöčĺé ňđĺáóĺňń˙ ńôîđěčđîâŕňü číôîđěŕöčîííîĺ ďđîńňđŕíńňâî [13, 14] äë˙ îďđĺäĺëĺíč˙ ęîíĺ÷íîăî âčäŕ ďđĺäńňŕâëĺíč˙ äŕííűő, ęîňîđűé čěĺĺň íĺîáőîäčěűé ôóíęöčîíŕë č ˙âë˙ĺňń˙ óäîáíűě äë˙ čńďîëüçîâŕíč˙ äŕííűő.
Ďîńęîëüęó äë˙ ôîđěčđîâŕíč˙ ŕńńîöčŕöčé ěĺćäó îáúĺęňŕěč č őŕđŕęňĺđčńňčęŕěč íĺîáőîäčěî đŕáîňŕňü ń đŕçíűěč čńňî÷íčęŕěč äŕííűő, â ęîňîđűő îäčí č ňîň ćĺ îáúĺęň ěîćĺň áűňü ďđĺäńňŕâëĺí ďîä đŕçíűěč íŕçâŕíč˙ěč, äë˙ ńđŕâíĺíč˙ ńőĺě čńňî÷íčęîâ äŕííűő öĺëĺńîîáđŕçíî čńďîëüçîâŕňü ďđîńňđŕíńňâî äŕííűő ń ęŕňŕëîăîě äŕííűő č ńëîâŕđĺě äŕííűő äë˙ ńđŕâíĺíč˙ íŕçâŕíčé îáúĺęňîâ.
Ęŕćäűé ó÷ŕńňíčę ďđîńňđŕíńňâŕ äŕííűő ďîääĺđćčâŕĺň ěîäĺëü äŕííűő č ˙çűę çŕďđîńîâ, ńîîňâĺňńňâóţůčé ôîđěčđóĺěîé ěîäĺëč. Çŕďđîń ę ňŕęîěó ďđîăđŕěěíîěó ńđĺäńňâó ďîääĺđćčâŕĺňń˙ â ôŕéëîâűő ńčńňĺěŕő îňíîńčňĺëüíî äčđĺęňîđčé: ńîďîńňŕâëĺíčĺ čěĺí, ďîčńę â äčŕďŕçîíĺ äŕň, ńîđňčđîâęŕ ďî đŕçěĺđó ôŕéëŕ č äđ. Íŕ ńëĺäóţůĺě óđîâíĺ ďđîńňđŕíńňâŕ äŕííűő ěîäĺëü äŕííűő äîëćíŕ ďîääĺđćčâŕňü ěóëüňčěíîćĺíčĺ ńëîâ ń öĺëüţ îńóůĺńňâëĺíč˙ ýôôĺęňčâíîăî ďîčńęŕ íĺîáőîäčěîé číôîđěŕöčč ďî ęëţ÷ĺâűě ńëîâŕě. Íčćĺ óđîâí˙ ěîäĺëč ěóëüňčěíîćĺíč˙ ńëîâ â čĺđŕđőčč ěîćĺň đŕńďîëŕăŕňüń˙ ěîäĺëü ńëŕáîńňđóęňóđčđîâŕííűő äŕííűő, îńíîâŕííŕ˙ íŕ îáîçíŕ÷ĺííűő ăđŕôŕő. Ďîńęîëüęó čńňî÷íčęč äŕííűő đŕçíîňčďíűĺ, íĺîáőîäčěî îďđĺäĺëčňü ďëŕňôîđěó č ŕđőčňĺęňóđó őđŕíčëčůŕ äŕííűő.
Ďëŕňôîđěŕ ďîääĺđćŕíč˙ őđŕíčëčůŕ äŕííűő — ýňî íŕáîđ ďđîăđŕěěíîăî îáĺńďĺ÷ĺíč˙ äë˙ őđŕíĺíč˙ č ďîčńęŕ äŕííűő â číôîđěŕöčîííîě ďđîńňđŕíńňâĺ [15].
Ŕđőčňĺęňóđŕ ďđîńňđŕíńňâŕ äŕííűő ńďđîĺęňčđîâŕíŕ óđîâí˙ěč (đčń. 3). Óđîâĺíü ďđčëîćĺíčé ďđĺäíŕçíŕ÷ĺí äë˙ đĺŕëčçŕöčč îďĺđŕöčé íŕä äŕííűěč â ďđîńňđŕíńňâĺ äŕííűő. Óđîâĺíü îíňîëîăčé čńďîëüçóĺňń˙ äë˙ óńňŕíîâëĺíč˙ ńâ˙çč ěĺćäó čńňî÷íčęŕěč.
Ďîńëĺäíčé óđîâĺíü ńîäĺđćčň čńňî÷íčęč äŕííűő č îáĺńďĺ÷čâŕĺň äîńňóď ę äŕííűě č âűďîëíĺíčţ îďĺđŕöčé óđîâí˙ ďđčěĺíĺíčé íĺďîńđĺäńňâĺííî â čńňî÷íčęĺ (íŕďđčěĺđ, îďĺđŕöč˙ âűáîđęč íŕ óđîâíĺ đĺŕëčçŕöčč âűďîëí˙ĺňń˙ ęŕę çŕďđîń â ęîíęđĺňíîé áŕçĺ äŕííűő).
3. Ŕëăîđčňě ďĺđĺőîäŕ îň îáúĺęňŕ ę ěîäĺëč NoSQL
Äë˙ îáĺńďĺ÷ĺíč˙ ďîńëĺäîâŕňĺëüíîăî ďĺđĺőîäŕ îň îáúĺęňŕ äŕííűő (íĺńňđóęňóđčđîâŕííűő äŕííűő) ę ôčçč÷ĺńęîé ěîäĺëč íĺîáőîäčěî ńîçäŕňü ŕëăîđčňě ďĺđĺőîäŕ îň îáúĺęňŕ ę ęîíęđĺňíîěó ďđĺäńňŕâëĺíčţ äŕííűő, ÷ňî ěîćíî đĺŕëčçîâŕňü â âčäĺ ěîäóë˙, ęîňîđűé îňâĺ÷ŕĺň çŕ ďđĺîáđŕçîâŕíčĺ â ôčçč÷ĺńęóţ ěîäĺëü NoSQL.  ńîîňâĺňńňâčč ń îáîńíîâŕíčĺě ââĺäĺí ëîăč÷ĺńęčé ďđîěĺćóňî÷íűé óđîâĺíü ěĺćäó ęîíöĺďňóŕëüíűě č ôčçč÷ĺńęčě óđîâí˙ěč. Ýňîň óđîâĺíü íŕďđŕâëĺí íŕ ňĺőíč÷ĺńęîĺ îďčńŕíčĺ ńňđóęňóđű äŕííűő áĺç óęŕçŕíč˙ őŕđŕęňĺđčńňčę, őŕđŕęňĺđíűő äë˙ ęŕćäîé ŃÓÁÄ. Äđóăčěč ńëîâŕěč, ěîäóëü Object-to-NoSQL đŕáîňŕĺň â äâŕ ďîńëĺäîâŕňĺëüíűő řŕăŕ: ęîíöĺďňóŕëüíűé > ëîăč÷ĺńęčé, ŕ çŕňĺě ëîăč÷ĺńęčé > ôčçč÷ĺńęčé. Ďĺđĺőîä îň îäíîé ěîäĺëč ę äđóăîé îńóůĺńňâë˙ĺňń˙ ń čńďîëüçîâŕíčĺě ďđĺîáđŕçîâŕíčé ňčďŕ M2M, ôîđěŕëčçîâŕííűő â QVT.
Ýëĺěĺíň ěîäóë˙ Object-to-NoSQL ďđĺäńňŕâë˙ĺň ńîáîé äčŕăđŕěěó ęëŕńńîâ. Ďîëüçîâŕňĺëü ďđĺäîńňŕâë˙ĺň âőîäíóţ ăđóďďó äŕííűő, ęîíęđĺňčçčđó˙ ęîíöĺďňóŕëüíóţ ěĺňŕ-ěîäĺëü PIM. Äŕííŕ˙ ěĺňŕ-ěîäĺëü ďîęŕçűâŕĺň îńíîâíűĺ ýëĺěĺíňű, ńîńňŕâë˙ţůčĺ ěîäĺëü äŕííűő, ŕ ňŕęćĺ čő ńňđóęňóđíűĺ őŕđŕęňĺđčńňčęč.
Îęîí÷ŕňĺëüíűé đĺçóëüňŕň, âîçâđŕůŕĺěűé ěîäóëĺě Object-to-NoSQL, ďđĺäńňŕâë˙ĺň ńîáîé ôčçč÷ĺńęóţ ěîäĺëü NoSQL (ęîëîíęč, äîęóěĺíňű, ăđŕôčęč čëč çíŕ÷ĺíčĺ ęëţ÷ŕ), ęîňîđŕ˙ âęëţ÷ŕĺň â ńĺá˙:
· Ěîäĺëü äŕííűő, ńîäĺđćŕůóţ íĺîáőîäčěűĺ ýëĺěĺíňű äë˙ đĺŕëčçŕöčč áŕçű äŕííűő NoSQL.
· Íŕáîđ đóęîâîä˙ůčő ďđčíöčďîâ, îďđĺäĺë˙ţůčő óńëîâč˙ čńďîëüçîâŕíč˙ ŕňđčáóňîâ č đĺŕëčçŕöčč îňíîřĺíčé â ńîîňâĺňńňâčč ń ďđčĺěŕěč, ďđčńóůčěč âűáđŕííîé ŃÓÁÄ NoSQL.
Î÷ĺâčäíî, ÷ňî äë˙ çŕäŕííîăî âűâîäŕ (ôčçč÷ĺńęîé ěîäĺëč NoSQL) íĺîáőîäčěî ńîőđŕíčňü ĺăî ďŕđŕěĺňđű, ň.ĺ. ĺăî ěĺňŕ-ěîäĺëü č ďđŕâčëŕ ďđĺîáđŕçîâŕíč˙, ęîňîđűĺ ďîçâîë˙ţň ĺăî ăĺíĺđčđîâŕňü. Äë˙ čëëţńňđčđîâŕíč˙ đŕáîňű âűáđŕíî ďđîčçâîäńňâî ôčçč÷ĺńęčő ěîäĺëĺé ń î÷ĺíü ÷ĺňęčěč őŕđŕęňĺđčńňčęŕěč, čńďîëüçó˙ ŃÓÁÄ Cassandra, SSDB, Neo4j č Redis. Ĺńëč ďîëüçîâŕňĺëü őî÷ĺň čńďîëüçîâŕňü äđóăóţ ŃÓÁÄ, ěîäóëü íĺîáőîäčěî äîďîëíčňü íîâűěč ďŕđŕěĺňđŕěč, ńďĺöčôč÷íűěč äë˙ ýňîé ńčńňĺěű.
Ěîäóëü Object-to-NoSQL ńîńňîčň čç äâóő ďđĺîáđŕçîâŕíčé: Object-to-GenericModel č GenericModel-to-PhysicalModel. Íŕ ďĺđâîě ýňŕďĺ âőîäíŕ˙ DCL ňđŕíńôîđěčđóĺňń˙ â îáůóţ NoSQL ěîäĺëü, ńîîňâĺňńňâóţůóţ ëîăč÷ĺńęîé PIM-ěîäĺëč. Íŕ âňîđîě ýňŕďĺ â ęŕ÷ĺńňâĺ âőîäíîé číôîđěŕöčč ďđčíčěŕĺňń˙ îáůŕ˙ ěîäĺëü č ăĺíĺđčđóţňń˙ ýëĺěĺíňű, íĺîáőîäčěűĺ äë˙ đĺŕëčçŕöčč ÁÄ, ŕ ňŕęćĺ íŕáîđ đóęîâîä˙ůčő ďđčíöčďîâ ďîääĺđćęč, ńďĺöčôč÷íűő äë˙ âűáđŕííîé ŃÓÁÄ NoSQL. Ýňč äâŕ ďđĺîáđŕçîâŕíč˙ âűďîëí˙ţňń˙ íŕáîđîě ďđŕâčë M2M, ôîđěŕëčçîâŕííűő â QVT, ňŕęčě îáđŕçîě äâŕ ďđĺîáđŕçîâŕíč˙ áĺńřîâíî ńâ˙çŕíű ěĺćäó ńîáîé.
Ńňîčň îáđŕňčňü âíčěŕíčĺ, ÷ňî ěîäóëü ďđĺîáđŕçîâŕíč˙ DCL ńďîńîáĺí ďđĺîáđŕçîâűâŕňü DCL â ôčçč÷ĺńęóţ ěîäĺëü [13] äë˙ îäíîé čç ďëŕňôîđě đĺŕëčçŕöčč NoSQL: ńňîëáöîâ, äîęóěĺíňîâ, ăđŕôčęîâ č ęëţ÷ĺâűő çíŕ÷ĺíčé. Ęŕę óćĺ óďîěčíŕëîńü âűřĺ, â ýňîé đŕáîňĺ đŕńńěîňđĺíű ŃÓÁÄ NoSQL ęŕćäîăî ňčďŕ: Cassandra äë˙ ęîëîíîę, SSDB äë˙ äîęóěĺíňîâ, Neo4j äë˙ ăđŕôčęîâ č Redis äë˙ ęëţ÷ĺé/çíŕ÷ĺíčé. Âűáđŕííîĺ đĺřĺíčĺ ńîâěĺńňčěî č ń äđóăčěč ŃÓÁÄ NoSQL, ňŕęčěč ęŕę HBase (îđčĺíňčđîâŕííŕ˙ íŕ ńňîëáöű) č CouchDB (îđčĺíňčđîâŕííŕ˙ íŕ äîęóěĺíňű).
Đŕńńěîňđčě ýňŕďű đĺŕëčçŕöčč ěîäóë˙ ďđĺîáđŕçîâŕíč˙ Object-to-NoSQL. Ýňŕ đĺŕëčçŕöč˙ ňđĺáóĺň ďđĺäâŕđčňĺëüíîăî îďđĺäĺëĺíč˙ íŕáîđŕ ěĺňŕ-ěîäĺëĺé č ďđŕâčë ďđĺîáđŕçîâŕíč˙ Ě2Ě-ňčďŕ.
Ńíŕ÷ŕëŕ íĺîáőîäčěî ńîçäŕňü ěĺňŕ-ěîäĺëč ECORE. Ýňî ěĺňŕ-ěîäĺëč ęîíöĺďňóŕëüíîăî MIP, ëîăč÷ĺńęîăî MIP äë˙ Cassandra, SSDB, Neo4j č Redis. Ýňč ěĺňŕ-ěîäĺëč îďčńűâŕţň, ńîîňâĺňńňâĺííî, ńňđóęňóđó UML MCI, îáůóţ NoSQL ěîäĺëü č ôčçč÷ĺńęčĺ ěîäĺëč Cassandra, SSDB, Neo4j č Redis.
Čńďîëüçóĺě ˙çűę QVT äë˙ đĺŕëčçŕöčč ďđŕâčë ďđĺîáđŕçîâŕíč˙, îáĺńďĺ÷čâŕţůčő äâŕ ďđîőîäŕ: ęîíöĺďňóŕëüíűé ę ëîăč÷ĺńęîěó č ëîăč÷ĺńęčé ę ôčçč÷ĺńęîěó. Ďđĺäëîćčě ńëĺäóţůčĺ řŕăč:
Ďîńëĺ ôîđěŕëčçŕöčč ęîíöĺďöčé, ďđčńóňńňâóţůčő â čńőîäíîé ěîäĺëč (UML Class Diagram) č â öĺëĺâîé ěîäĺëč (Generic NoSQL model) ďđĺîáđŕçîâŕíč˙ UML-to-GenericModel, çäĺńü ďđĺäńňŕâëĺí ŕâňîěŕňč÷ĺńęčé ďĺđĺőîä îň ęîíöĺďňóŕëüíîăî PIM ę ëîăč÷ĺńęîěó PIM. Ýňîň ďĺđĺőîä âűďîëí˙ĺňń˙ öĺďî÷ęîé ďđĺîáđŕçîâŕíčé:
1. Řŕă 1: Ęŕćäŕ˙ äčŕăđŕěěŕ ęëŕńńŕ DCL ďđĺîáđŕçóĺňń˙ â áŕçó äŕííűő, ăäĺ BD.N = DCL.N.
2. Řŕă 2: Ęŕćäűé ęëŕńń c ∈ C ďđĺîáđŕçóĺňń˙ â ňŕáëčöó t ∈ T, ăäĺ t.N = c.N:
a. ęŕćäűé ŕňđčáóň ęëŕńńŕ ac ∈ c.Ac ďđĺîáđŕçóĺňń˙ â ňŕáëč÷íűé ŕňđčáóň at, ăäĺ at.N = ac.N, at.Ty = ac.C, ŕ çŕňĺě äîáŕâë˙ĺňń˙ â ńďčńîę ŕňđčáóňîâ ĺăî ďđĺîáđŕçîâŕííîăî ęîíňĺéíĺđŕ t, ęîňîđűé at ∈ t. At;
b. čäĺíňčôčęŕňîđ îáúĺęňŕ c ňđŕíńôîđěčđóĺňń˙ â čäĺíňčôčęŕňîđ ńňđîęč t, ăäĺ Idt.N = Idc.N č Idt.Ty = Rid, çŕňĺě äîáŕâë˙ĺňń˙ â ńďčńîę t ŕňđčáóňîâ ňčďŕ 𝐼𝑑𝑡 ∈ t.At.
3. Řŕă 3: Ęŕćäŕ˙ ńâ˙çü l ∈ L ńňĺďĺíč 2, ńâ˙çűâŕţůŕ˙ äâŕ ęëŕńńŕ c1 č c2, ňđŕíńôîđěčđóĺňń˙ â ńâ˙çü r ∈ R, ńâ˙çűâŕţůóţ ňŕáëčöű t1 č t2, ńîîňâĺňńňâóţůčĺ ęëŕńńŕě c1 č c2, ăäĺ r.N = l.N, r. Cpr = {(t1, 𝑐𝑟𝑐1),( t2, 𝑐𝑟𝑐2 )}.
4. Řŕă 4: Ęŕćäîĺ ńîĺäčíĺíčĺ l ∈ L ńňĺďĺíč n (ďđč n > 2) ďđčâîäčň ę (1) ďî˙âëĺíčţ íîâîé ňŕáëčöű tl ń ńîáńňâĺííűě čäĺíňčôčęŕöčîííűě ŕňđčáóňîě 𝐼𝑑tl, ăäĺ tl.N = l.N, tl.A = {Idtl} č (2) íŕáîđ čç n äâîč÷íűő ńâ˙çĺé {r1, ... , rn }, ∀ i ∈ [1..n] ri ńâ˙çűâŕĺň tl â äđóăóţ ňŕáëčöó tl, ńîîňâĺňńňâóţůóţ đîäńňâĺííîěó ęëŕńńó ci , ăäĺ ri.N = (tl.N)_(ti.N) č ri. Cpr = {(tl, null), (ti, null)}.
5. Řŕă 5: Ęŕćäűé ęëŕńń cŕssî ŕńńîöčŕöčé ěĺćäó n ęëŕńńŕěč {c1, ... , cn} (ń n ≥ 2) ňđŕíńôîđěčđóĺňń˙ ęŕę çâĺíî ńňĺďĺíč ńňđîăî âűřĺ 2 â (1) íîâóţ ňŕáëčöó tŕssî, ăäĺ tŕssî.N = l.N, tŕsso.A = cŕssî.Ŕŕssî č (2) íŕáîđ n äâîč÷íűő îňíîřĺíčé {r1, ... , rn}, ∀ i ∈ [1...n] ri ńâ˙çűâŕĺň tŕssî ń äđóăîé ňŕáëčöĺé ti, ńîîňâĺňńňâóţůĺé đîäńňâĺííîěó ęëŕńńó ci, ăäĺ ri.N = (tasso.N)_(ti.N) č ri. Cpr = {(tŕssî, null), (ti, null)}.
Îęîí÷ŕňĺëüíűé đĺçóëüňŕň ńîńňîčň čç ěîäĺëč äŕííűő, ńîäĺđćŕůĺé ýëĺěĺíňű, íĺîáőîäčěűĺ äë˙ đĺŕëčçŕöčč ÁÄ, č íŕáîđŕ đóęîâîä˙ůčő ďđčíöčďîâ, ńďĺöčôč÷íűő äë˙ ŃÓÁÄ SSDB.
Ďđĺîáđŕçîâŕíčĺ îáúĺęňŕ â îáůóţ ěîäĺëü (1) ˙âë˙ĺňń˙ ďĺđâűě řŕăîě â ďđîöĺńńĺ Object-to-NoSQL. Îí ňđŕíńëčđóĺň äčŕăđŕěěó âőîäíîăî ęëŕńńŕ UML â îáůóţ ěîäĺëü NoSQL (2); ýňŕ ěîäĺëü ńîîňâĺňńňâóĺň ëîăč÷ĺńęîé PIM-ěîäĺëč. Ďđĺîáđŕçîâŕíčĺ îáůĺé ěîäĺëč â ôčçč÷ĺńęóţ (3) ˙âë˙ĺňń˙ âňîđűě ýňŕďîě, ęîňîđűé ăĺíĺđčđóĺň ôčçč÷ĺńęčĺ ěîäĺëč NoSQL (PSM) (4) č íŕáîđ îăđŕíč÷ĺíčé (5) čç îáůĺé ěîäĺëč.
Âűâîäű
 đĺçóëüňŕňĺ čńńëĺäîâŕíč˙ ńóůĺńňâóţůčő ěĺňîäîâ îáúĺäčíĺíč˙ đŕçëč÷íűő čńňî÷íčęîâ číôîđěŕöčč âű˙âëĺíŕ ďđîáëĺěŕ îňńóňńňâč˙ ďđčíöčďčŕëüíűő ďîäőîäîâ ę číňĺăđŕöčč äŕííűő â ĺäčíîĺ číôîđěŕöčîííîĺ ďđîńňđŕíńňâî.
Íŕ îńíîâĺ đŕńńěîňđĺíč˙ äĺéńňâóţůčő ěîäĺëĺé ďđĺîáđŕçîâŕíč˙ číôîđěŕöčč ďîńňđîĺí ďîäőîä ę číňĺăđŕöčč číôîđěŕöčč â âčäĺ ěîäĺëč «îáúĺęň-őŕđŕęňĺđčńňčęŕ», ęîňîđŕ˙ äŕĺň âîçěîćíîńňü îáđŕáŕňűâŕňü äŕííűĺ đŕçíűő ôîđěŕňîâ.
Đĺřĺíŕ çŕäŕ÷ŕ îďđĺäĺëĺíč˙ ěîäĺëč ŕńńîöčŕöčč îáúĺęňîâ č őŕđŕęňĺđčńňčę îńíîâíűő ďđĺäńňŕâëĺíčé äŕííűő. Ďîńňđîĺíŕ íîâŕ˙ číôîđěŕöčîííŕ˙ ńňđóęňóđŕ číňĺëëĺęňóŕëüíîăî ńčňóŕöčîííîăî öĺíňđŕ.
Đŕçđŕáîňŕíű číńňđóěĺíňű ěíîăîóđîâíĺâîăî ďđĺîáđŕçîâŕíč˙ číôîđěŕöčč, ęîňîđűĺ ńîńňî˙ň čç öĺďî÷ęč ďđĺîáđŕçîâŕíčé ń čńďîëüçîâŕíčĺě îáůĺé ěîäĺëč, đŕńďîëîćĺííîé íŕ ďđîěĺćóňî÷íîě óđîâíĺ ěĺćäó DCL (ęîíöĺďňóŕëüíűě óđîâíĺě) č ěîäĺëüţ đĺŕëčçŕöčč číôîđěŕöčč â áŕçű äŕííűő (ôčçč÷ĺńęčě óđîâíĺě).
Ďđĺäëîćĺíŕ ěĺňîäčęŕ ôîđěčđîâŕíč˙ ôčçč÷ĺńęčő ěîäĺëĺé číôîđěŕöčč čç đŕçíîđîäíîé íĺńňđóęňóđčđîâŕííîé č ńëŕáîńňđóęňóđčđîâŕííîé číôîđěŕöčč. Ýňŕ ěĺňîäčęŕ ńîâěĺńňčěŕ ń ÷ĺňűđüě˙ ňčďŕěč ŃÓÁÄ NoSQL: ęîëîíęŕěč, äîęóěĺíňŕěč, ăđŕôčęŕěč č ęëţ÷ĺâűě çíŕ÷ĺíčĺě.
Ěîäĺëč äŕííűő (ęîíöĺďňóŕëüíűĺ, ëîăč÷ĺńęčĺ č ôčçč÷ĺńęčĺ), čńďîëüçóĺěűĺ â đŕçđŕáîňŕííîě ďđîöĺńńĺ, ńîîňâĺňńňâóţň ěĺňŕ-ěîäĺë˙ě, ęîňîđűĺ ďđĺäëîćĺíű äë˙ âűďîëíĺíč˙ öĺëĺé đŕńńěîňđĺííűő ýňŕďîâ: îň ęîíöĺďňóŕëüíîăî ę ëîăč÷ĺńęîěó, ŕ çŕňĺě îň ëîăč÷ĺńęîăî ę ôčçč÷ĺńęîěó.
References
1. Silverston L. (2001) The Data Model Resource Book, Revised Edition. Volume 1: A Library of Universal Data Models for All Enterprises. — John Wiley & Sons, New York, 2001. — 542 p. — ISBN 978-0-471-38023-8.
2. Hay D. C. (2011) Enterprise Model Patterns: Describing the World (UML Version). — Technics Publications, LLC, Bradley Beach, USA, 2011. — 532 p. — ISBN 978-1-9355040-5-4.
3. Blaha M. (2010) Patterns of Data Modeling (Emerging Directions in Database Systems and Applications). — CRC Press, Washington, 2010. — 261 p. — ISBN 978-1-4398198-9-0.
4. Fowler M. (1996). Analysis Patterns: Reusable Object Models. — Addison-Wesley Professional, 1996. — 384 p. — ISBN 978-0-201-89542-1.
5. Simankov V. S., Drilenko M. V. (2020) Metodicheskie osnovy vybora platform predstavleniya informatsii v intellektual'nom situatsionnom tsentre // Sovremennaya nauka: aktual'nye problemy teorii i praktiki. Seriya: Estestvennye i Tekhnicheskie Nauki. — 2020. — ą8. — S. 108–112. — ISSN 2223-2966. — DOI: 10.37882/2223-2966.2020.08.30.
6. Simankov V. S., Drilenko M. V. (2020) Metodicheskie osnovy preobrazovaniya informatsionnykh potokov ot kontseptual'noi k fizicheskoi modeli dannykh v intellektual'nom situatsionnom tsentre // Perspektivy nauki. — 2020. — ą7 (130) — S. 39–43. — ISSN 2077-6810.
7. Levin N. A., Munerman V. I., Sergeev V. P. (2004) Algebra mnogomernykh matrits kak universal'noe sredstvo modelirovaniya dannykh i ee realizatsiya v sovremennykh SUBD // Sistemy i sredstva informatiki. Moskva: Nauka. — 2004. — Vyp. 14. — S. 86–99. — ISBN 5-02-032836-7.
8. Magoulas R., Lorica B. (2009) Big data: Technologies and techniques for large scale data // Jimmy Guterman, Release 2.0. — Issue 11. — O'Reilly Media, Inc., 2009. — ISBN 9780596520540.
9. Dittrich J. P., Kossmann D., Kreutz A. (2005) Bridging the gap between OLAP and SQL // Proceedings of the 31st International Conference on Very Large Data Bases. Trondheim, Norway, August 30 – September 2, 2005. — p. 1031–1042. — ISBN 978-1-59593-154-2.
10. Hooman J., van de Pol J. Equivalent semantic models for a distributed dataspace architecture // International Symposium on Formal Methods for Components and Objects. — Springer, Berlin, Heidelberg, 2002. — p. 182–201. — ISBN 978-3-540-20303-2. — DOI: 10.1007/978-3-540-39656-7_7.
11. The Open Archives Initiative Protocol for Metadata Harvesting Protocol Version 2.0 of 2002-06-14. [Elektronnyi resurs]. URL: http://www.openarchives.org/OAI/openarchivesprotocol.html (data obrashcheniya 20.10.2020).
12. Kumarasinghe C. U., Liyanage K. L. D. U., Madushanka W. A. T., Mendis R. A. C. L. (2015) Performance Comparison of NoSQL Databases in Pseudo Distributed Mode: Cassandra, MongoDB & Redis. [Elektronnyi resurs]. URL: https://www.researchgate.net/profile/Tiroshan_Madushanka/publication/281629653_Performance_Comparison_of_NoSQL_Databases_in_Pseudo_Distributed_Mode_Cassandra_MongoDB_Redis/links/55f113ba08aedecb68ffd294/Performance-Comparison-of-NoSQL-Databases-in-Pseudo-Distributed-Mode-Cassandra-MongoDB-Redis.pdf (data obrashcheniya 20.10.2020).
13. Cooper B. F., Silberstein A., Tam E., Ramakrishnan R., Sears R. (2010) Benchmarking cloud serving systems with YCSB. // Proceedings of the 1st ACM symposium on Cloud computing (SoCC ’10). — Association for Computing Machinery, New York, NY, USA, 2010. — p. 143–154. — DOI: 10.1145/1807128.1807152.
14. Chinonso O., Osemwegie O., Okokpujie K., John S. (2017) Development of an Encrypting System for an Image Viewer based on Hill Cipher Algorithm // Covenant Journal of Engineering Technology. — 2017. — Volume 1. — ą 2. — p. 65–73. — ISSN 2682-5325.
15. Inmon W. H. (2005) Building the Data Warehouse. 4th Edition. — John Wiley & Sons, Indianapolis, 2005. — 576 p. — ISBN 978-0-76459944-6.
|

 Eng
Eng









